Document AI & RAG for a Newspaper Archive
A Saturday morning of workshops and corridor conversations with Mauritius's developer community at SWAN HQ in Port-Louis. My own session was on Document AI and RAG for a historical newspaper archive — turning a 1955 Le Figaro into something a researcher can actually query.


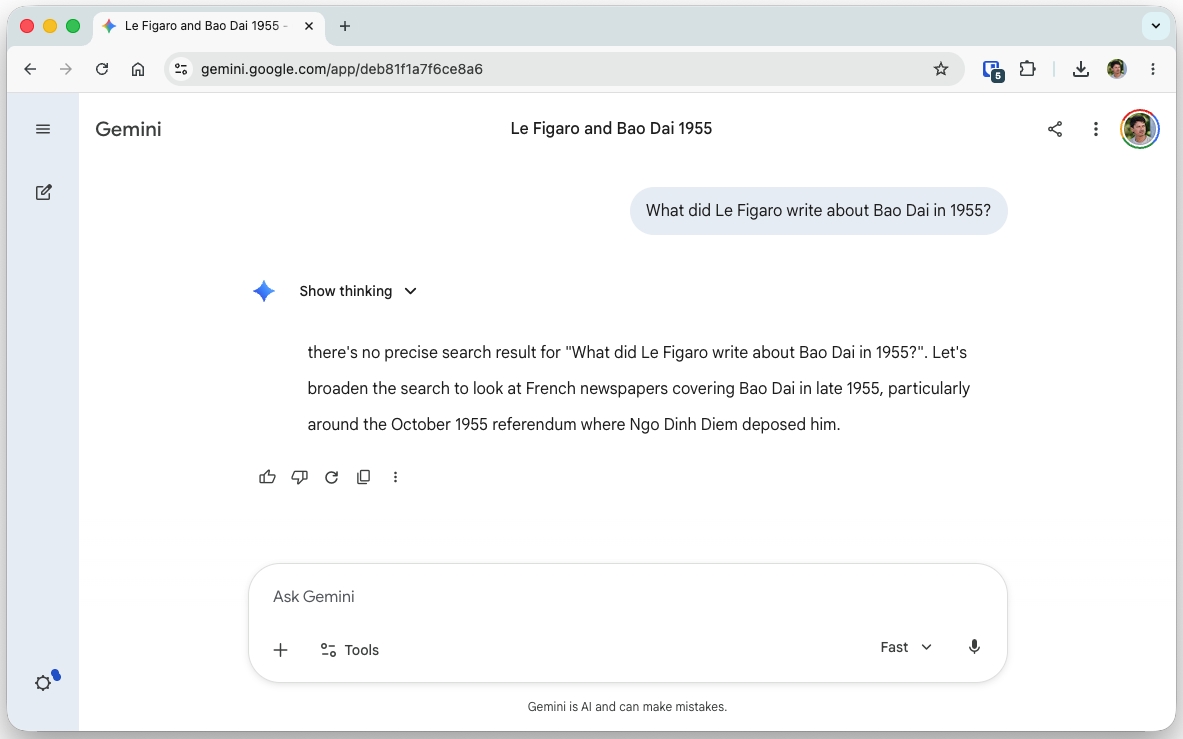
On Saturday May 9 2026, I participated in the Google Build with AI event organised by GDG Mauritius and hosted by SWAN, at their Port-Louis Head-Office. 36 people attended the event. My presentation was titled "Document AI & RAG for a Newspaper Archive." I started the talk with a soft "Hello" and pulled up the Google Chrome browser on the screen with a tab showing Gemini. It had a question, "What did Le Figaro write about Bao Dai in 1955?"
There's no precise search result for 'What did Le Figaro write about Bao Đại in 1955?'. Let's broaden the search to look at French newspapers covering Bao Dai in late 1955, particularly around the October 1955 referendum where Ngo Dinh Diem deposed him.
I let that sink in for a moment. Then I switched to my terminal and ran a small Python script — same question, against a tool I had built and trained on actual 1955 issues of Le Figaro. The answer came back in about four seconds. Concise. Specific. Footnoted, with each citation linking back to the precise page in the original PDF where the claim came from.

Different tool. Different answer. Same question.
That contrast was the whole reason I was doing that presentation.
A quick note on framing
I opened the talk by introducing myself and where I work — La Sentinelle Ltd, publisher of l'express, 5-Plus, Business Magazine, Turf Magazine, and a few other Mauritian titles. And I was up front about one thing: this is a personal hobby project. Nights and weekends, no La Sentinelle mandate. If it grows into something the company or other regional publishers want to adopt one day, brilliant. For now it's just me, a laptop, and a stubborn belief that queryable newspaper archives are worth building.
Why old newspapers are hard
Generally-available chatbots are excellent at the surface of public knowledge. Ask Gemini about the 1955 Vietnamese referendum and it'll tell you Ngô Đình Diệm "won" with an implausible 98.2% of the vote. Ask it what Le Figaro specifically wrote about it on a specific date, with citations, and it falls over.
Two reasons. The training data isn't there — archives like the BnF's Gallica hold millions of 1950s pages, but as PDFs of microfilm with only basic OCR. And modern OCR doesn't help much either — tools trained on contemporary invoices and magazines aren't ready for a seven-column 1955 broadsheet. They read horizontally across columns and produce what I call column-bleed.
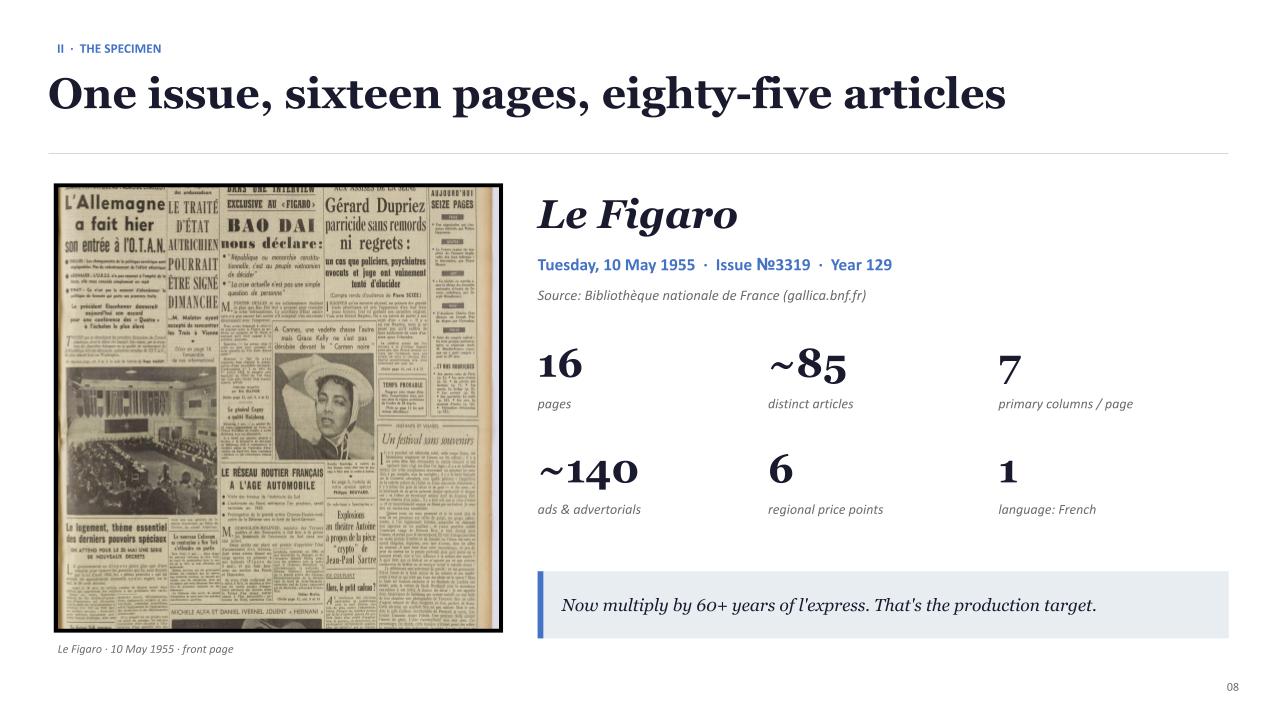
A real pdftotext output from the 10 May 1955 Le Figaro:
L'Allemagne LE TRAITÉ DANS UNE INTERVIEW Gérard Dupriez AUJOURD'HUI / a fait hier D'ÉTAT EXCLUSIVE BAO DAI parricide SEIZE PAGES.
Four unrelated articles spliced together. Articles don't even live in one column — the Bao Đại interview starts in column 3 of page 1, runs into column 4, then jumps to "page 13, columns 3, 4 and 5" via a tiny « Suite page 13 » pointer. One article. Two pages. Five columns. Then there are the ads — about 40% of every page, much of it dressed up as editorial. Orlane sells beauty cream under the headline « À peau soignée, beau maquillage ». Pullnyl's « La révélation de l'année » reads like a scoop until you notice it's selling nylon shirts at 1,200 francs. If your pipeline can't tell these from editorial, your knowledge base ships ad copy as facts.
The pipeline
Five stages, end to end:
- Ingest — PDFs land in Cloud Storage.
- Parse — Document AI Layout Parser. Hierarchical block structure, cross-column reading order.
- Enrich — Gemini 2.5 multimodal. Article assembly, kind classification, jump resolution. This is where the actual contribution lives.
- Index — Cloud SQL Postgres 18 with pgvector.
- Generate — Gemini grounded answers with inline citations.

Stages 1, 4 and 5 are well-trodden. Stages 2 and 3 are where teams fall down on newspaper data.
A few interesting moments from the build
Most of the provisioning is the kind of gcloud you've seen a hundred times. Three things stood out as worth showing.
Cloud SQL Postgres 18 with pgvector. Postgres 18 went GA on Cloud SQL this year, and pgvector is now a first-class extension:
gcloud sql instances create figaro-db \
--database-version=POSTGRES_18 \
--tier=db-custom-1-3840 --region=us-central1 \
--root-password="$(openssl rand -base64 24)"
The actual technical contribution sits in the schema — a French tsvector column and a 768-dimensional embedding column in the same row, each with the right index:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE articles (
-- ... id, source, page, published, title, body ...
kind TEXT CHECK (kind IN
('news','feature','opinion','advertorial','ad','listing')),
tsv TSVECTOR GENERATED ALWAYS AS (
setweight(to_tsvector('french', coalesce(title,'')), 'A') ||
setweight(to_tsvector('french', coalesce(body,'')), 'B')
) STORED,
embedding VECTOR(768)
);
CREATE INDEX ON articles USING GIN (tsv);
CREATE INDEX ON articles USING hnsw (embedding vector_cosine_ops);
The whole retrieval story rests on those two columns existing side-by-side, each with the appropriate index. GIN for full-text, HNSW for cosine similarity.
Document AI has no gcloud surface. This is the kind of friction nobody warns you about. Want to create a Layout Parser processor? gcloud documentai processors create does not exist — not in gcloud, not in gcloud alpha, not anywhere. You hit the REST API directly:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-d '{"displayName":"figaro-layout-parser","type":"LAYOUT_PARSER_PROCESSOR"}' \
"https://us-documentai.googleapis.com/v1/projects/$PROJECT_ID/locations/us/processors"
Two quirks worth knowing. The endpoint is us-documentai.googleapis.com (multi-region) — Document AI doesn't expose per-region endpoints like us-central1. And the locations/us in the path matches that.
Passing two modalities to Gemini
For each page, the ingest splits the source PDF to a single page (Document AI's sync endpoint caps at 40 MB), parses the layout, renders the page as JPEG, and hands Gemini both inputs together:
def extract_articles(layout_chunks, page_image, page_num):
prompt = f"""Group blocks into articles from this 1955 French newspaper.
Use the page image as authoritative for grouping. For each article return:
title, body, byline, kind (news|feature|opinion|advertorial|ad|listing),
and jump_target if a « Suite page X » pointer is visible. Translate nothing.
Layout chunks for page {page_num}: {json.dumps(layout_chunks)[:12000]}"""
response = gen.models.generate_content(
model="gemini-2.5-flash",
contents=[
types.Part.from_bytes(data=page_image, mime_type="image/jpeg"),
prompt,
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
temperature=0.2,
),
)
return json.loads(response.text)
The image gives Gemini visual context the JSON can't carry — ad framing, advertorial styling, « Suite page X » pointers, the way a section break looks different from a paragraph break. The model literally sees what a 1955 newspaper reader saw. The kind value in the output is the linchpin: classifying ads vs editorial at ingest time keeps ad copy out of every future retrieval, forever.
Retrieval is hybrid by necessity
The query that runs against the database has two CTEs side by side:
WITH lexical AS (
SELECT id, ROW_NUMBER() OVER (
ORDER BY ts_rank_cd(tsv, q) DESC) AS rk
FROM articles, plainto_tsquery('french', :query) q
WHERE tsv @@ q
AND kind IN ('news','feature','opinion')
AND published BETWEEN :from AND :to
LIMIT 50
),
semantic AS (
SELECT id, ROW_NUMBER() OVER (
ORDER BY embedding <=> :qvec::vector) AS rk
FROM articles
WHERE kind IN ('news','feature','opinion')
AND published BETWEEN :from AND :to
ORDER BY embedding <=> :qvec::vector LIMIT 50
)
SELECT a.*,
COALESCE(1.0/(60+l.rk), 0) + COALESCE(1.0/(60+s.rk), 0) AS score
FROM lexical l FULL OUTER JOIN semantic s USING (id)
JOIN articles a ON a.id = COALESCE(l.id, s.id)
ORDER BY score DESC LIMIT 12;
Three things matter here. tsvector with 'french' gives exact-term precision — type Bao Đại and every chunk with that tokenisation surfaces. embedding <=> qvec cosine gives paraphrase tolerance — "what did the South Vietnamese ruler say about elections" still finds chunks discussing « régime républicain ou monarchie constitutionnelle ». And kind IN (...) on both CTEs filters Pullnyl's nylon-shirt ads out of editorial answers before either ranker sees them.
The fusion is Reciprocal Rank Fusion with k=60 — a parameter-free way to combine rankers that produce scores on incommensurable scales. A document at rank 2 in lexical and rank 3 in semantic beats a document at rank 1 in lexical and rank 50 in semantic. The constant 60 comes from the original 2009 RRF paper and remains the empirically robust default.
Lexical for precision. Semantic for paraphrase. RRF to fuse them without calibrating score scales.
The Mauritius angle
Two hundred years of Mauritian newsprint sitting in PDFs and microfilm. Le Cernéen from 1832 to 1982 — the oldest paper in the southern hemisphere. Le Mauricien from 1908. l'express from 1963. Plus the National Library of Mauritius, the Mahatma Gandhi Institute archives, the official gazette since 1773. Almost none of it queryable today.
For institutions like the National Library or the MGI, data residency matters. The production version of this pipeline runs end-to-end in africa-south1 — one network hop from Mauritius, historical content never leaves the region. Building this index is, in a real sense, an act of recovery: putting our history into a form our great-grandchildren can actually ask questions of.
What's next
A few directions on my list:
- A knowledge graph layer — entities, dates, geographies, navigable visually.
- Multimodal photo Q&A — "show me Cannes festival photos 1950 to 1960".
- Cross-paper queries across Le Figaro, l'express, Le Cernéen, the gazette.
- Era-aware retrieval — 1955 vocabulary differs from 2025 vocabulary in ways that matter for embedding quality.
The hobby project continues. By DevFest 2026, I'm hoping to have something more structured than a Python script firing a single query — a proper service layer, a frontend a researcher can actually navigate, maybe the cross-paper piece running across two or three titles. We'll see how far I get.
Thanks
Thank you to SWAN HQ for hosting a great Build with AI event in Port-Louis, to the Google Developer Group community for putting the day together, and to everyone who came up after the talk with questions, war stories, and corrections that I'm still chewing on. The slides are at the end of this post; the demo source code goes up on GitHub this week.
Gallery




Attendees at the Build with AI 2026 edition
Jochen Kirstätter with opening remarks and Devesh from SWAN welcoming the atteendees
Noor Yadallee doing a live demo of America Sign Language using MediaPipe and Gemini Nano from a Flutter application running from his mobile phone
Ish Sookun presenting a case study of asking a specific question on generic AI chatbots vs a model trained on newspaper archives
Ish Sookun using the example of the freely available Le Figaro archive of 1955 from the Bibliothèque nationale de France (BnF)
Build with AI 2026 — Mauritius / SWAN Head Office, Port-Louis (Group Picture)